本文由 发布。
1.Flink架构及特性分析
Flink是个相当早的项目,开始于2008年,但只在最近才得到注意。Flink是原生的流处理系统,提供high level的API。Flink也提供 API来像Spark一样进行批处理,但两者处理的基础是完全不同的。Flink把批处理当作流处理中的一种特殊情况。在Flink中,所有 的数据都看作流,是一种很好的抽象,因为这更接近于现实世界。
1.1 基本架构
下面我们介绍下Flink的基本架构,Flink系统的架构与Spark类似,是一个基于Master-Slave风格的架构。

当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager, JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。 TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。
Client 为提交 Job 的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)。提交 Job 后,Client 可以结束进程 (Streaming的任务),也可以不结束并等待结果返回。
JobManager 主要负责调度 Job 并协调 Task 做 checkpoint,职责上很像 Storm 的 Nimbus。从 Client 处接收到 Job 和 JAR 包 等资源后,会生成优化后的执行计划,并以 Task 的单元调度到各个 TaskManager 去执行。
TaskManager 在启动的时候就设置好了槽位数(Slot),每个 slot 能启动一个 Task,Task 为线程。从 JobManager 处接收需要 部署的 Task,部署启动后,与自己的上游建立 Netty 连接,接收数据并处理。
JobManager
JobManager是Flink系统的协调者,它负责接收Flink Job,调度组成Job的多个Task的执行。同时,JobManager还负责收集Job 的状态信息,并管理Flink集群中从节点TaskManager。JobManager所负责的各项管理功能,它接收到并处理的事件主要包括:
RegisterTaskManager
在Flink集群启动的时候,TaskManager会向JobManager注册,如果注册成功,则JobManager会向TaskManager回复消息 AcknowledgeRegistration。
SubmitJob
Flink程序内部通过Client向JobManager提交Flink Job,其中在消息SubmitJob中以JobGraph形式描述了Job的基本信息。
CancelJob
请求取消一个Flink Job的执行,CancelJob消息中包含了Job的ID,如果成功则返回消息CancellationSuccess,失败则返回消息 CancellationFailure。
UpdateTaskExecutionState
TaskManager会向JobManager请求更新ExecutionGraph中的ExecutionVertex的状态信息,更新成功则返回true。
RequestNextInputSplit
运行在TaskManager上面的Task,请求获取下一个要处理的输入Split,成功则返回NextInputSplit。
JobStatusChanged
ExecutionGraph向JobManager发送该消息,用来表示Flink Job的状态发生的变化,例如:RUNNING、CANCELING、 FINISHED等。
TaskManager
TaskManager也是一个Actor,它是实际负责执行计算的Worker,在其上执行Flink Job的一组Task。每个TaskManager负责管理 其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向JobManager汇报。TaskManager端可以分成两个 阶段:
注册阶段
TaskManager会向JobManager注册,发送RegisterTaskManager消息,等待JobManager返回AcknowledgeRegistration,然 后TaskManager就可以进行初始化过程。
可操作阶段
该阶段TaskManager可以接收并处理与Task有关的消息,如SubmitTask、CancelTask、FailTask。如果TaskManager无法连接 到JobManager,这是TaskManager就失去了与JobManager的联系,会自动进入“注册阶段”,只有完成注册才能继续处理Task 相关的消息。
Client
当用户提交一个Flink程序时,会首先创建一个Client,该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群中处 理,所以Client需要从用户提交的Flink程序配置中获取JobManager的地址,并建立到JobManager的连接,将Flink Job提交给 JobManager。Client会将用户提交的Flink程序组装一个JobGraph, 并且是以JobGraph的形式提交的。一个JobGraph是一个 Flink Dataflow,它由多个JobVertex组成的DAG。其中,一个JobGraph包含了一个Flink程序的如下信息:JobID、Job名称、配 置信息、一组JobVertex等。
1.2 基于Yarn层面的架构
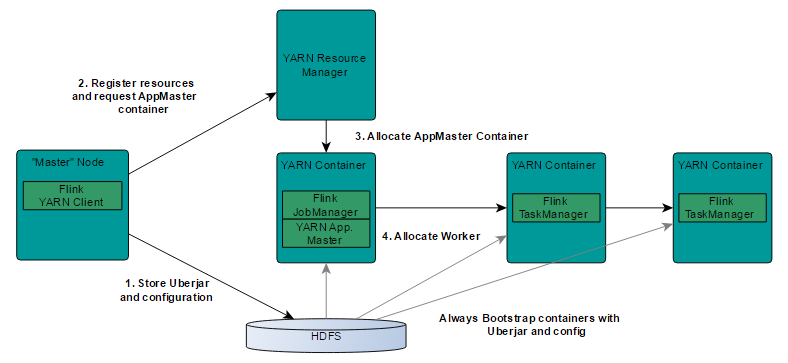
基于yarn层面的架构类似spark on yarn模式,都是由Client提交App到RM上面去运行,然后RM分配第一个container去运行 AM,然后由AM去负责资源的监督和管理。需要说明的是,Flink的yarn模式更加类似spark on yarn的cluster模式,在cluster模式 中,dirver将作为AM中的一个线程去运行,在Flink on yarn模式也是会将JobManager启动在container里面,去做个driver类似 的task调度和分配,YARN AM与Flink JobManager在同一个Container中,这样AM可以知道Flink JobManager的地址,从而 AM可以申请Container去启动Flink TaskManager。待Flink成功运行在YARN集群上,Flink YARN Client就可以提交Flink Job到 Flink JobManager,并进行后续的映射、调度和计算处理。
1.3 组件栈
Flink是一个分层架构的系统,每一层所包含的组件都提供了特定的抽象,用来服务于上层组件。
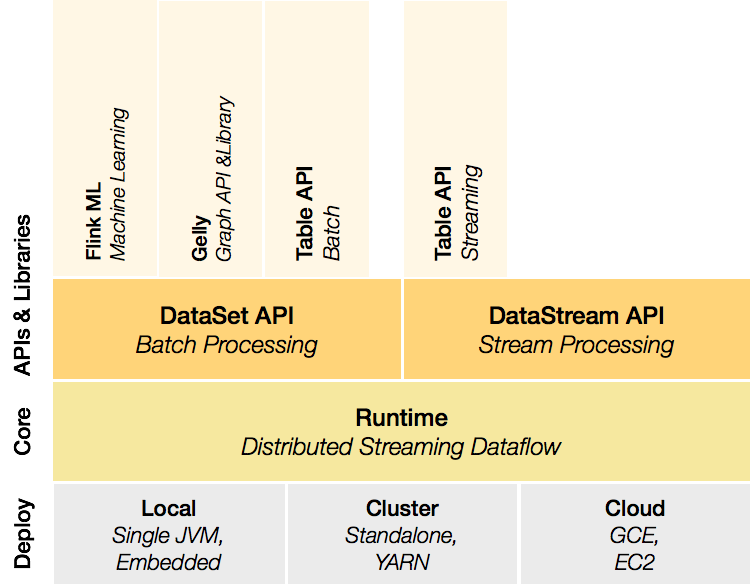
Deployment层
该层主要涉及了Flink的部署模式,Flink支持多种部署模式:本地、集群(Standalone/YARN)、云(GCE/EC2)。Standalone 部署模式与Spark类似,这里,我们看一下Flink on YARN的部署模式
Runtime层
Runtime层提供了支持Flink计算的全部核心实现,比如:支持分布式Stream处理、JobGraph到ExecutionGraph的映射、调度等 等,为上层API层提供基础服务。
API层
API层主要实现了面向无界Stream的流处理和面向Batch的批处理API,其中面向流处理对应DataStream API,面向批处理对应DataSet API。
Libraries层
该层也可以称为Flink应用框架层,根据API层的划分,在API层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理 和面向批处理两类。面向流处理支持:CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作);面向批处理支持: FlinkML(机器学习库)、Gelly(图处理)。
从官网中我们可以看到,对于Flink一个最重要的设计就是Batch和Streaming共同使用同一个处理引擎,批处理应用可以以一种特 殊的流处理应用高效地运行。
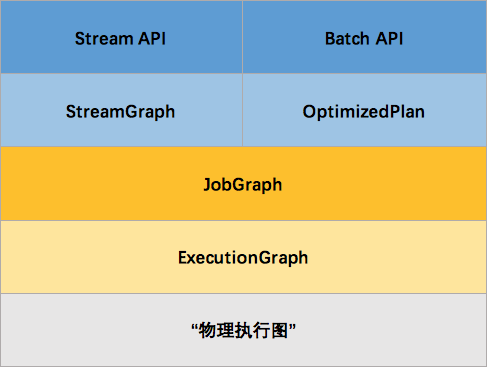
这里面会有一个问题,就是Batch和Streaming是如何使用同一个处理引擎进行处理的。
1.4 Batch和Streaming是如何使用同一个处理引擎。
下面将从代码的角度去解释Batch和Streaming是如何使用同一处理引擎的。首先从Flink测试用例来区分两者的区别。
Batch WordCount Examples
Streaming WordCount Examples
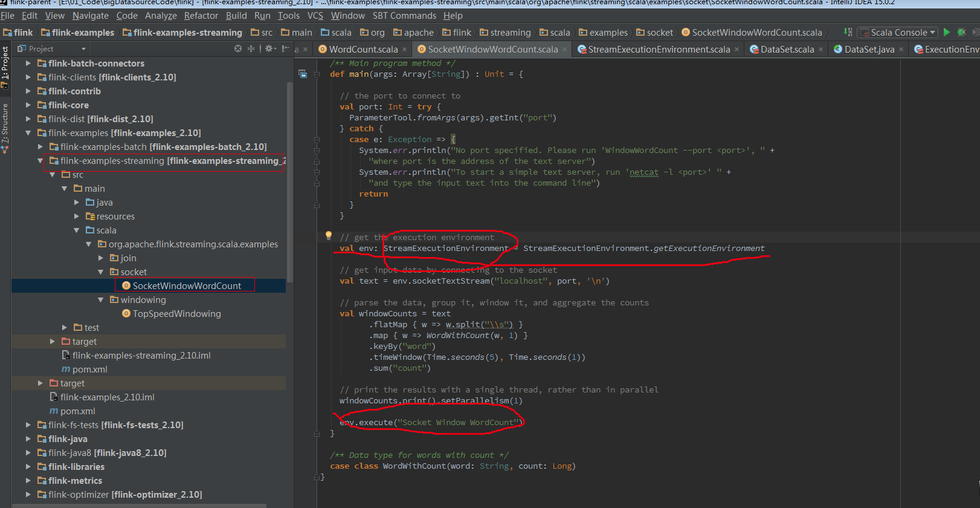
Batch和Streaming采用的不同的ExecutionEnviroment,对于ExecutionEnviroment来说读到的源数据是一个DataSet,而 StreamExecutionEnviroment的源数据来说则是一个DataStream。

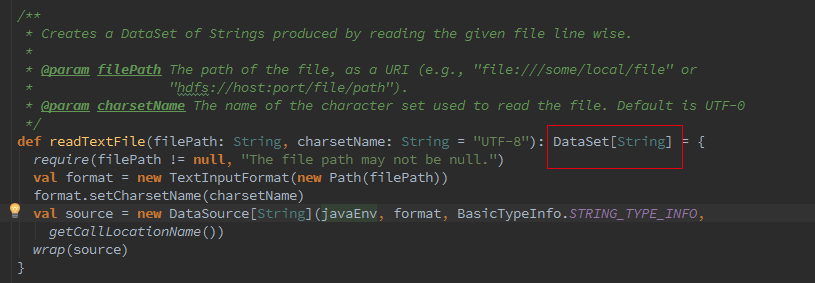

接着我们追踪下Batch的从Optimzer到JobGgraph的流程,这里如果是Local模式构造的是LocalPlanExecutor,这里我们只介绍 Remote模式,此处的executor为RemotePlanExecutor

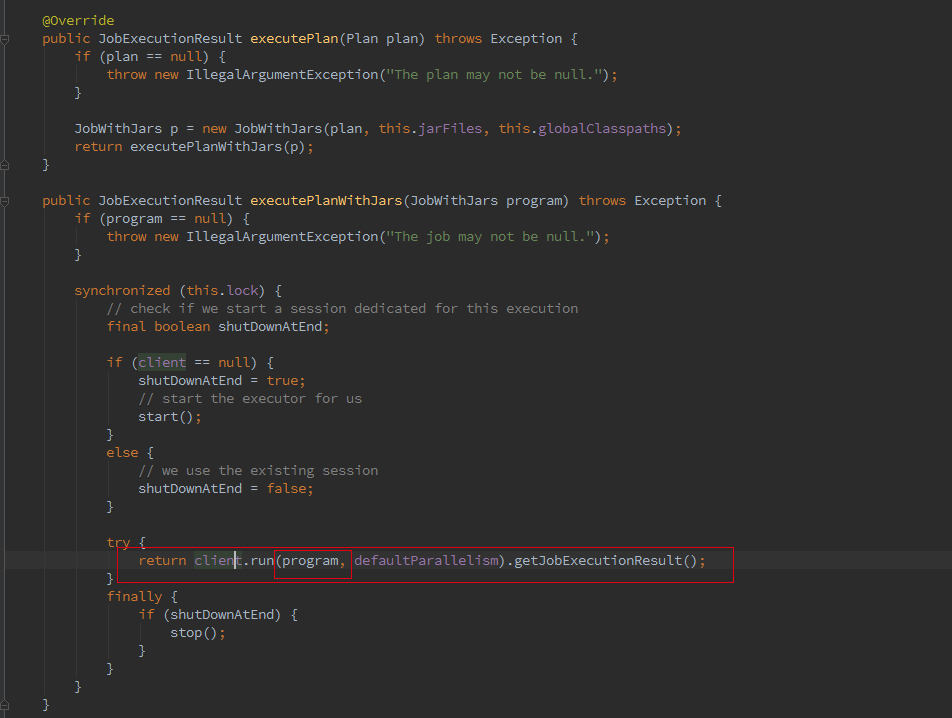
最终会调用ClusterClient的run方法将我们的应用提交上去,run方法的第一步就是获取jobGraph,这个是client端的操作,client 会将jobGraph提交给JobManager转化为ExecutionGraph。Batch和streaming不同之处就是在获取JobGraph上面。

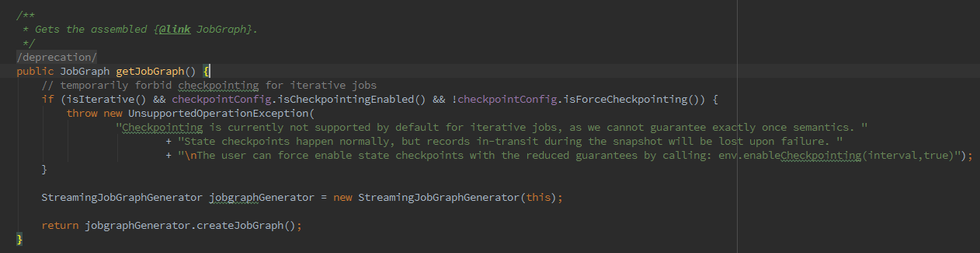
如果我们初始化的FlinkPlan是StreamingPlan,则首先构造Streaming的StreamingJobGraphGenerator去将optPlan转为 JobGraph,Batch则直接采用另一种的转化方式。

简而言之,Batch和streaming会有两个不同的ExecutionEnvironment,不同的ExecutionEnvironment会将不同的API翻译成不同 的JobGgrah,JobGraph 之上除了 StreamGraph 还有 OptimizedPlan。OptimizedPlan 是由 Batch API 转换而来的。 StreamGraph 是由 Stream API 转换而来的,JobGraph 的责任就是统一 Batch 和 Stream 的图。
1.5 特性分析
高吞吐 & 低延迟
Flink 的流处理引擎只需要很少配置就能实现高吞吐率和低延迟。下图展示了一个分布式计数的任务的性能,包括了流数据 shuffle 过程。

支持 Event Time 和乱序事件
Flink 支持了流处理和 Event Time 语义的窗口机制。
Event time 使得计算乱序到达的事件或可能延迟到达的事件更加简单。
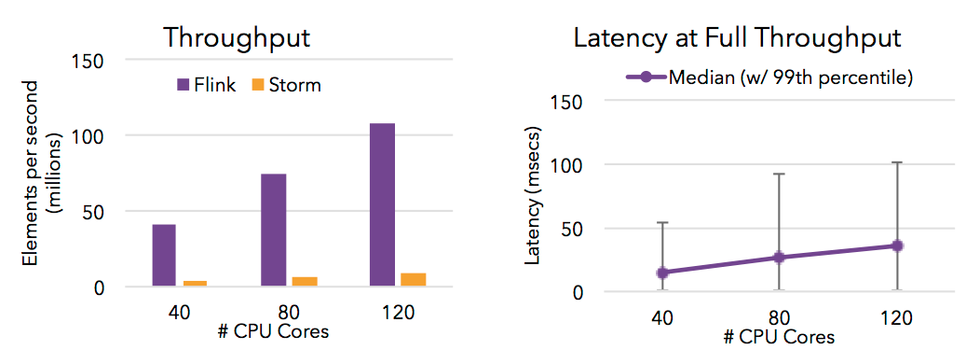
状态计算的 exactly-once 语义
流程序可以在计算过程中维护自定义状态。
Flink 的 checkpointing 机制保证了即时在故障发生下也能保障状态的 exactly once 语义。

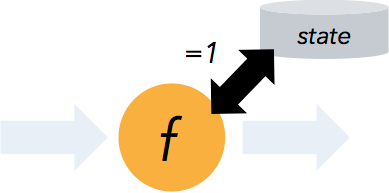
高度灵活的流式窗口
Flink 支持在时间窗口,统计窗口,session 窗口,以及数据驱动的窗口
窗口可以通过灵活的触发条件来定制,以支持复杂的流计算模式。
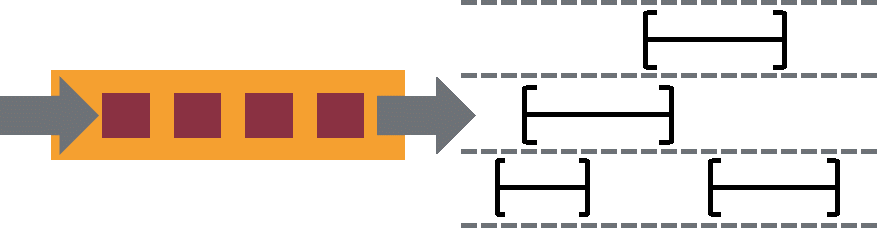
带反压的连续流模型
数据流应用执行的是不间断的(常驻)operators。
Flink streaming 在运行时有着天然的流控:慢的数据 sink 节点会反压(backpressure)快的数据源(sources)。
容错性
Flink 的容错机制是基于 Chandy-Lamport distributed snapshots 来实现的。
这种机制是非常轻量级的,允许系统拥有高吞吐率的同时还能提供强一致性的保障。
Batch 和 Streaming 一个系统流处理和批处理共用一个引擎
Flink 为流处理和批处理应用公用一个通用的引擎。批处理应用可以以一种特殊的流处理应用高效地运行。

内存管理
Flink 在 JVM 中实现了自己的内存管理。
应用可以超出主内存的大小限制,并且承受更少的垃圾收集的开销。
迭代和增量迭代
Flink 具有迭代计算的专门支持(比如在机器学习和图计算中)。
增量迭代可以利用依赖计算来更快地收敛。

程序调优
批处理程序会自动地优化一些场景,比如避免一些昂贵的操作(如 shuffles 和 sorts),还有缓存一些中间数据。
API 和 类库
流处理应用
DataStream API 支持了数据流上的函数式转换,可以使用自定义的状态和灵活的窗口。
右侧的示例展示了如何以滑动窗口的方式统计文本数据流中单词出现的次数。
val texts:DataStream[String] = ...
val counts = text .flatMap { line => line.split("\\W+") } .map { token => Word(token, 1) } .keyBy("word") .timeWindow(Time.seconds(5), Time.seconds(1)) .sum("freq")
批处理应用
Flink 的 DataSet API 可以使你用 Java 或 Scala 写出漂亮的、类型安全的、可维护的代码。它支持广泛的数据类型,不仅仅是 key/value 对,以及丰富的 operators。
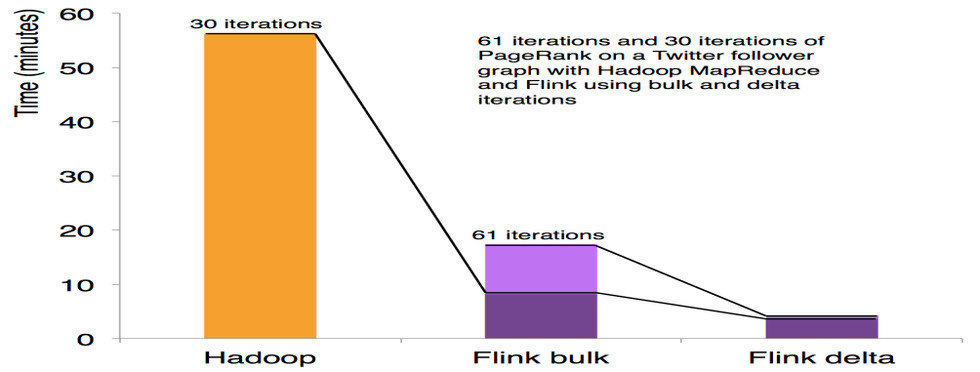
右侧的示例展示了图计算中 PageRank 算法的一个核心循环。
case class Page( pageId: Long, rank:Double) case class Adjacency( id: Long, neighbors:Array[Long])
val result = initialRanks.iterate(30) { pages => pages.join(adjacency).where("pageId").equalTo("pageId") { (page, adj, out : Collector[Page]) => { out.collect(Page(, 0.15 / numPages)) for (n <- adj.neighbors) { out.collect(Page(n, 0.85*page.rank/adj.neighbors.length)) } } } .groupBy("pageId").sum("rank") }
类库生态
Flink 栈中提供了提供了很多具有高级 API 和满足不同场景的类库:机器学习、图分析、关系式数据处理。当前类库还在 beta 状 态,并且在大力发展。

广泛集成
Flink 与开源大数据处理生态系统中的许多项目都有集成。
Flink 可以运行在 YARN 上,与 HDFS 协同工作,从 Kafka 中读取流数据,可以执行 Hadoop 程序代码,可以连接多种数据存储 系统。

部署
Flink可以单独脱离Hadoop进行部署,部署只依赖Java环境,相对简单。
本文未结束,余下内容请见--
网易有数
企业级大数据可视化分析平台。面向业务人员的自助式敏捷分析平台,采用PPT模式的报告制作,更加易学易用,具备强大的探索分析功能,真正帮助用户洞察数据发现价值。
点击这里---
了解 网易云 :
网易云官网:新用户大礼包:网易云社区: